Overview
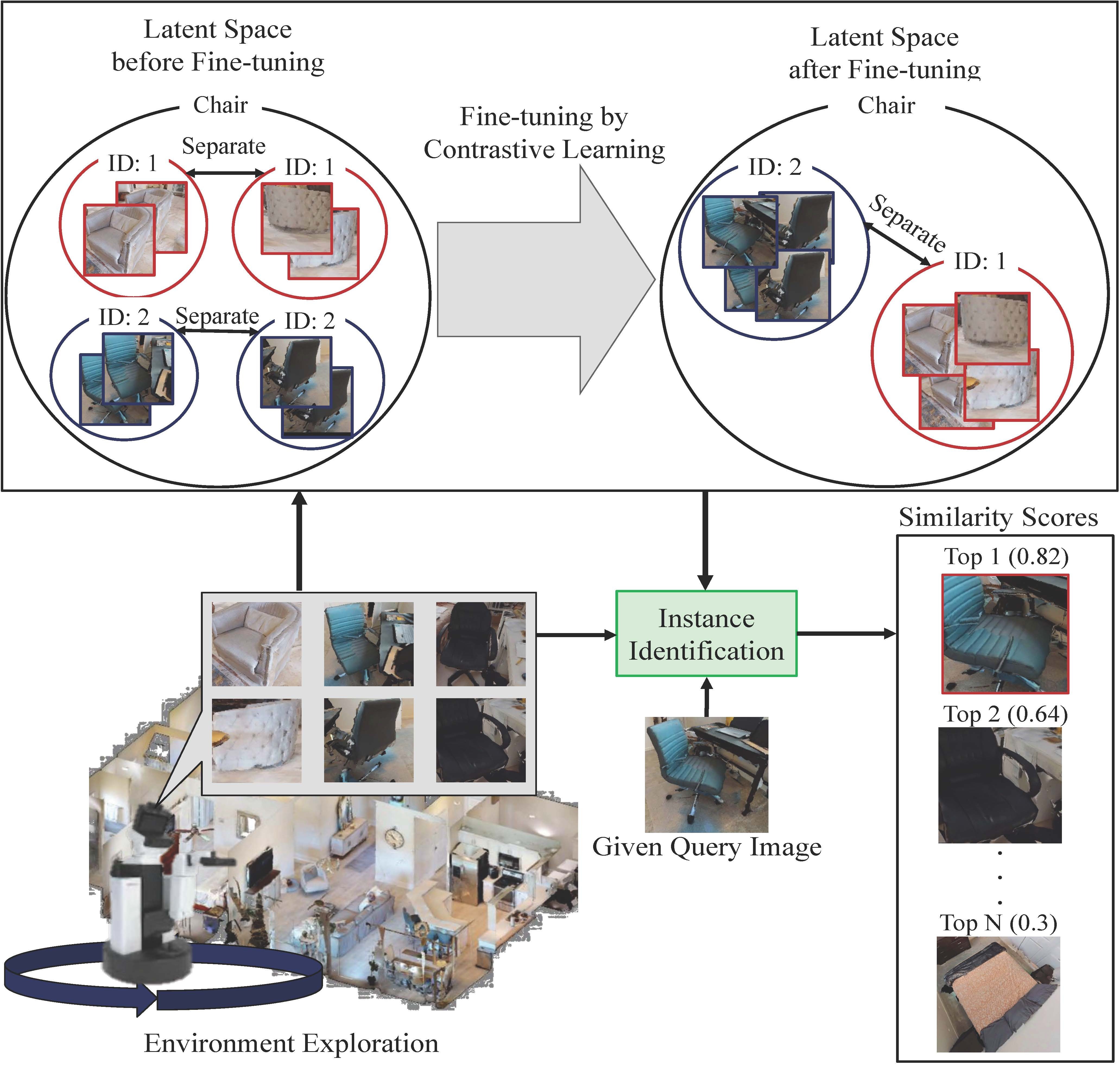
Robots that assist in daily life are required to locate specific instances of objects that match the user's desired object in the environment. This task is known as Instance-Specific Image Goal Navigation (InstanceImageNav), which requires a model capable of distinguishing between different instances within the same class. One significant challenge in robotics is that when a robot observes the same object from various 3D viewpoints, its appearance may differ greatly, making it difficult to recognize and locate the object accurately. In this study, we introduce a method, SimView, that leverages multi-view images based on a 3D semantic map of the environment and self-supervised learning by SimSiam to train an instance identification model on-site. The effectiveness of our approach is validated using a photorealistic simulator, Habitat Matterport 3D, created by scanning real home environments. Our results demonstrate a 1.7-fold improvement in task accuracy compared to CLIP, which is pre-trained multimodal contrastive learning for object search. This improvement highlights the benefits of our proposed fine-tuning method in enhancing the performance of assistive robots in InstanceImageNav tasks.


@inproceedings{sakaguchi2024simview,
author={Sakaguchi, Taichi and Taniguchi, Akira and Hagiwara, Yoshinobu and El Hafi, Lotfi and Hasegawa, Shoichi and Taniguchi, Tadahiro},
title={Object Instance Retrieval in Assistive Robotics: Leveraging Fine-Tuned SimSiam with Multi-View Images Based on 3D Semantic Map},
booktitle={IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
year={2024, in press}
}
This work was supported by JSPS KAKENHI Grants-in-Aid for Scientific Research (Grant Numbers JP23K16975, 22K12212) and JST Moonshot Research & Development Program (Grant Number JPMJMS2011).